透明度渲染
顺序无关的半透明混合(OIT)的相关方法包括Depth Peeling、Per-Pixel Linked List、Adaptive Transparency、Weighted Blended OIT、Pixel Synchronization
2023-10-7
大纲
顺序无关的半透明混合(OIT)相关方法
Depth Peeling:使用N个 PASS 将场景中的半透明物体根据深度分成 N 层,分别记录每层的颜色和深度,然后再将每层的颜色混合起来。
Per-Pixel Linked List:一个屏幕大小的链表头纹理,一个屏幕大小 N 倍的链表节点纹理。在链表头纹理的每个像素中存储每个像素链表在节点纹理中的偏移量。遇到半透明片元就将深度、颜色等写入对应像素的链表。最后再用一个 PASS 对每个像素的链表进行深度排序和颜色混合。
Adaptive Transparency:渲染半透明物体,建立逐像素链表,将片段颜色、深度写入对应的链表。读取 List,在本地内存空间生成近似能见度函数数组,并使用带能见度函数的混合公式混合片段计算出最终颜色。
Weighted Blended OIT
Pixel Synchronization
顺序无关的半透明混合(OIT)相关方法
游戏引擎在绘制场景的时候,会对整个场景的半透明物体从后到前排序渲染,这样可以保证混合公式按照预期的方式正确工作。因为混合公式是顺序敏感的。这种对半透明物体的排序,都是物体(Object)级别的,这样做大概只能解决 50% 的问题。
当某个半透明物体很大,旁边又有很多很小的半透明物体时,就会出现大物体视觉上本来应该挡住小物体,但排序时却被排到了后面的情况。这显然是不正确的。遇到这样的情况最粗暴的解决方法是,将大物体打散(变成多个小物体)来提高排序的精确度。虽然比较 粗暴,但半透明物体的问题应该可以解决到 75%。
如果出现自纠缠的复杂的半透明物体,就必须引入更加复杂的技术来解决问题了。即本文将要讨论的顺序无关的半透明混合技术(Order Independent Transparency,OIT)。OIT 技术的方案不止一种,下表大致罗列了这些技术的相关信息:
Depth Peeling
1
100
DX9 +
Stencil Routed
1
100
DX10.1 +
Per-Pixel Linked List
5
80 unbounded
DX11+
Adaptive Transparency
10
80
DX11+
Weighted Blended OIT
10
80
DX11+
Pixel Synchronization
10
50
DX12+
深度剥离方法 Depth Peeling
深度剥离方法,出自 NVIDIA,其核心思想是从相机触发,经过 N(可配置)个 PASS 将场景中的半透明物体根据深度分成了 N 层,分别记录每层的颜色和深度,然后再将每层的颜色混合起来。后来 NVIDIA 为了优化剥离性能,又提出了一种在一个 PASS 中同时剥离最前面一层和最后面一层的方法,被成为 Dual Depth Peeling。
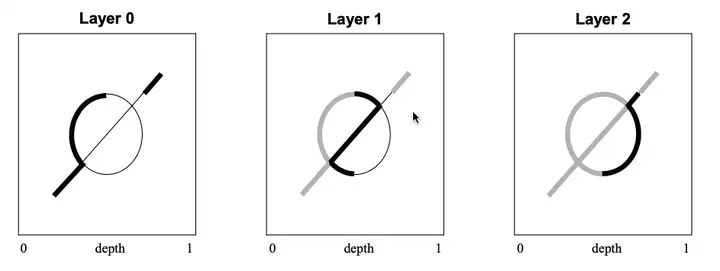
从左到右(layer 0-2)根据深度依次剥离最前面的一层
Depth Peeling 是一种很慢,非常费显存空间(空间分配可确定),但对硬件没什么高要求的 OIT 方法。
参考文献
Depth Peeling in NVDIA: http://developer.download.nvidia.com/assets/gamedev/docs/OrderIndependentTransparency.pdf
2008-02 Dual Depth Peeling in NVIDIA : https://my.eng.utah.edu/~cs5610/handouts/DualDepthPeeling.pdf
逐像素的链表 Per-Pixel Linked Lists OIT
逐像素的链表,运用到了一个被称为“GPU 并行链表“的技术,在 Pixel Shader 中使用两个可写的纹理(DX11,SM5.0,UAV),一个屏幕大小的链表头纹理,一个屏幕大小 N 倍的链表节点纹理。链表头纹理的每个像素存储每个像素链表在节点纹理中的偏移量。
这项技术可以用来解决图形渲染中的很多问题,用来解决 OIT 问题只是其诸多应用之一。核心做法是遇到半透明片元就将深度、颜色等写入对应像素的链表。最后再用一个 PASS 对每个像素的链表进行深度排序和颜色混合。
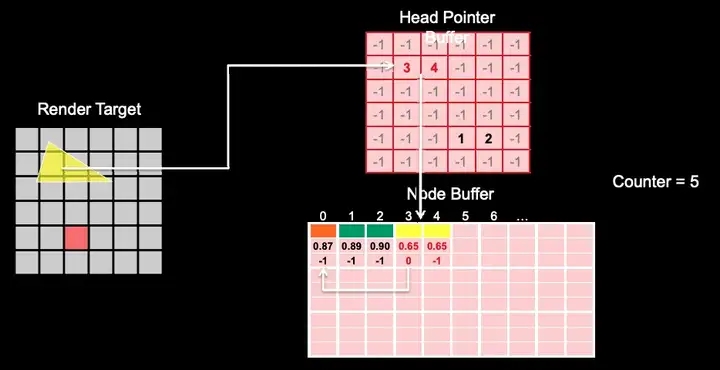
Per-Pixel Linked Lists 用于解决 OIT 问题,速度比 Depth Peeling 快了很多。显存空间也比 Depth Peeling 更加节省,但节点纹理具体需要多大无法事先做准确的预估,因此显存的具体消耗不可控。硬件要求 DX 11以上,SM 5.0。
参考文献
real-time concurrent linked list construction on the GPU: http://developer.amd.com/wordpress/media/2013/06/2041_final.pdf
自适应透明度 Adaptive Transparency
Adaptive Transparency,简称 AT,是 Intel 提出的一种 OIT 技术。其核心思想是通过修改经典混合公式本身来改进 Per-Pixel Linked Lists 方法的内存和性能问题。
经典混合公式: 在经典的混合公式中,颜色是一次一次有序的迭代混合到目标色上的。如果我们使用某种方法,打破这种有序迭代,我们就可以不用再对片段排序了,即做到了真正的顺序无关。在这个方法中引入了一个==能见度函数==来简化这个顺序无关的混合公式:
引入能见度的混合公式: 现在所有的问题都集中在能见度函数上了:一个在 [0, 1] 之间单调递减的函数。
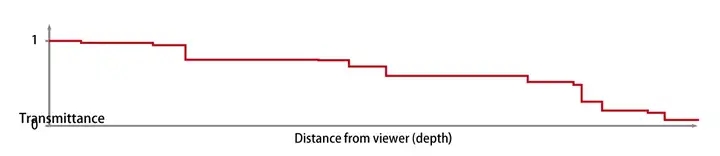
能见度函数:
因此我们可以这样计算 OIT 最终颜色了:
渲染半透明物体,建立 Per-Pixel Linked Lists,并将片段颜色、深度写入对应的 List。
读取 Lists 然后建立能见度函数 vis 。
再次读取 Pixel Lists 然后使用带有能见度函数的混合公式计算最终颜色。
但这并没有比 Per-Pixel Linked List 更优秀。一个很好的思路是==将能见度函数近似的表示为一个单调递减的定长数组==。比如:

在采用近似能见度函数后,OIT 计算理想情况下可以直接简化为:
渲染半透明物体,建立颜色、深度的能见度函数 vis(z),并将其存储到framebuffer中。
后处理,使用带有能见度的混合方程,计算最终颜色。
但是在 DX11 的硬件设备和 API 上不能支持我们完成上述方案的第一步:
如果使用framebuffer,其位宽有限,无法存储第一步产生的数据。
如果使用 UAV,GPU 片段计算是完全并行的(同一个像素的不同片段都是并行的),无法采用原子方法生成单调递减的 vis 函数。
因此,最终的 Adaptive Transparency 方法是:
渲染半透明物体,建立 Per-Pixel Linked Lists,并将片段颜色、深度写入对应的 List(这一步与 Per-Pixel Linked List OIT 一样)。
后处理:读取 List,在本地内存空间生成近似能见度函数数组,并使用带能见度函数的混合公式混合片段计算出最终颜色。
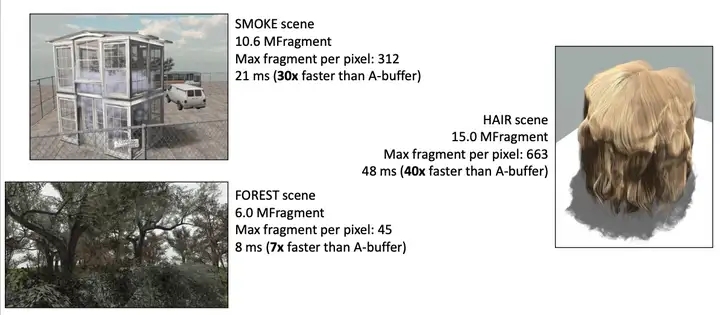
AT 方法在越复杂的场景中表现越好(A-buffer 即 Per-Pixel Linked List OIT)。
Adaptive Transparency 方法使用了近似的能见度函数,对 Per-Pixel Linked List 的混合步骤进行了简化,不需要再对每个像素的所有片段进行排序了,简化了混合计算复杂度,但也因此丢失了混合精度。从 paper 的测试数据看,AT 方法在越复杂的场景中,相比 Per-Pixel Linked Lists OIT 的效率越高。
参考文献
2011-02 Adaptive Transparency by intel presentation on GDC 2011: https://software.intel.com/content/dam/develop/external/us/en/documents/adaptivetransparency-gdc2011-182534.pdf
KlayGE: 继续探索OIT:Adaptive Transparency
Weighted Blended OIT
参考文献
Weighted Blended Order Independent Transparency: http://jcgt.org/published/0002/02/09/paper.pdf
Pixel Synchronization
参考文献
2013 SIGGRAPH Pixel Synchronization: Solving Old Graphics Problems with New Data Structures: http://advances.realtimerendering.com/s2013/2013-07-23-SIGGRAPH-PixelSync.pdf
最后更新于
这有帮助吗?